
COSMOS Packet Processors are a powerful concept that allow you to run code each time a specified packet is received. COSMOS provides a few generic Packet Processors which allows you to include statistics about individual telemetry points in your defined packets. Let’s break down how the COSMOS included processors are used and how you can implement your own Packet Processor.
First install COSMOS and start up the demo application. You’ll notice we declare a few targets of which one is called INST (for instrument). If you open up Packet Viewer and navigate to the INST target and the HEALTH_STATUS packet you can see a bunch of derived telemetry points at the top.
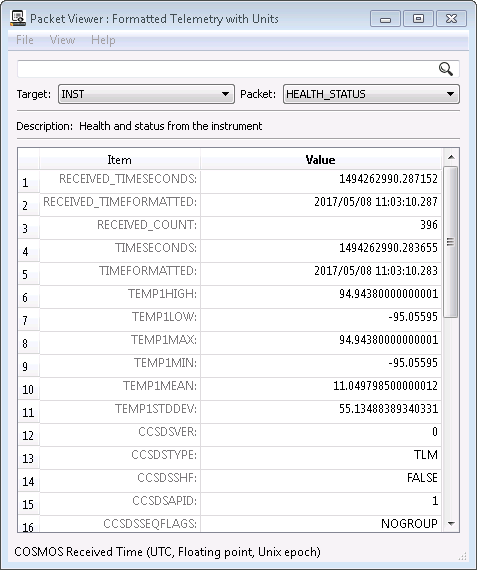
These points aren’t immediately obvious in the GUI (Ticket #441) but here they include all the items down to and including TEMP1STDDEV. If you right click on one of them and choose “Details” you can see that Data Type is DERVIED.
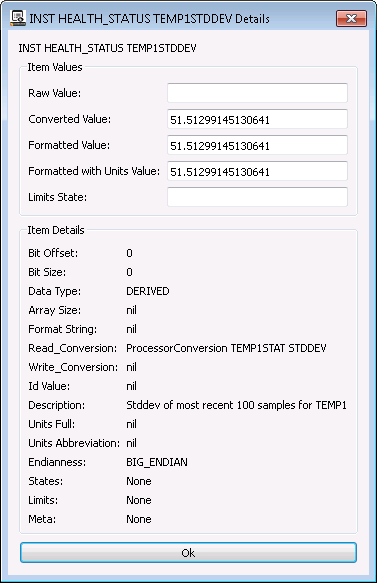
This is all controlled by the INST target’s cmd/tlm definition files. If you open the INST/cmd_tlm/inst_tlm.txt file from the demo you’ll see the following at the end of the HEALTH_STATUS packet definition:
ITEM TEMP1HIGH 0 0 DERIVED "High-water mark for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1WATER HIGH_WATER
ITEM TEMP1LOW 0 0 DERIVED "Low-water mark for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1WATER LOW_WATER
ITEM TEMP1MAX 0 0 DERIVED "Maximum of most recent 100 samples for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1STAT MAX
ITEM TEMP1MIN 0 0 DERIVED "Minimum of most recent 100 samples for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1STAT MIN
ITEM TEMP1MEAN 0 0 DERIVED "Mean of most recent 100 samples for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1STAT MEAN
ITEM TEMP1STDDEV 0 0 DERIVED "Stddev of most recent 100 samples for TEMP1"
READ_CONVERSION processor_conversion.rb TEMP1STAT STDDEV
PROCESSOR TEMP1STAT statistics_processor.rb TEMP1 100
PROCESSOR TEMP1WATER watermark_processor.rb TEMP1
These definitions create six new telemetry ITEMs. The READ_CONVERSION line takes a conversion class and then variable parameters that are passed to the class. Here we’re using the COSMOS provided processor_conversion.rb class which pulls a result calculated by a PROCESSOR. The last two lines define the two PROCESSORs.
Currently COSMOS provides the following three processors:
- new_packet_log_processor.rb - This processor creates a new packet log whenever the given Packet is seen.
- watermark_processor.rb - This processor monitors a telemetry item and tracks the high and low water points of that item since the launch of the Command and Telemetry Server.
- statistics_processor.rb - This processor collects a given number of samples of a telemetry item and calculates the minimum, maximum, mean, and standard deviation over the sample.
If all you want to do is to calculate useful statistics on your telemetry items you can stop reading now. For those who want to know how this works or want to implement their own Packet Processors, let’s continue into the source code.
Processor Implementation
require 'cosmos/processors/processor'
module Cosmos
class WatermarkProcessor < Processor
# @param item_name [String] The name of the item to gather statistics on
# @param value_type #See Processor::initialize
def initialize(item_name, value_type = :CONVERTED)
super(value_type)
@item_name = item_name.to_s.upcase
reset()
end
# See Processor#call
def call(packet, buffer)
value = packet.read(@item_name, @value_type, buffer)
high_water = @results[:HIGH_WATER]
@results[:HIGH_WATER] = value if !high_water or value > high_water
low_water = @results[:LOW_WATER]
@results[:LOW_WATER] = value if !low_water or value < low_water
end
# Reset any state
def reset
@results[:HIGH_WATER] = nil
@results[:LOW_WATER] = nil
end
# Convert to configuration file string
def to_config
" PROCESSOR #{@name} #{self.class.name.to_s.class_name_to_filename} #{@item_name} #{@value_type}\n"
end
end
end
The initialize method gets passed the parameters from the config file. Thus our config file of:
PROCESSOR TEMP1WATER watermark_processor.rb TEMP1
passes ‘TEMP1’ into ‘item_name’ of the initialize method:
def initialize(item_name, value_type = :CONVERTED)
Since we only pass one value, we use the default value_type of :CONVERTED.
We store the item_name into a Ruby instance variable @item_name and call reset() to initialize our @results. But how did we get a @results instance variable? If you look at the class definition we are inheriting from Processor which is the base class for all COSMOS Processors. It declares a @results instance variable and initializes @results in its initialize method which we call using super(value_type).
The call method is the most important Processor method. It is always passed the packet and buffer. The packet is the COSMOS Packet instance which contains the value you’re interested in. Buffer is the raw binary buffer which this packet is based on. The Processor base class should never be directly used as it defines but does not implement call. Instead, you inherit from Processor like we did with WatermarkProcessor and implement your own call method. WatermarkProcessor reads the item we’re interested in and then compares it with the currently stored high and low value to determine if it should be saved. Note how it is saving the value in the @results hash with the :HIGH_WATER and :LOW_WATER symbol keys.
Processor Conversion
If you then open up the processor_conversion.rb code you can see how these results are converted into new telemetry items.
require 'cosmos/conversions/conversion'
module Cosmos
# Retrieves the result from an item processor
class ProcessorConversion < Conversion
# @param processor_name [String] The name of the associated processor
# @param result_name [String] The name of the associated result in the processor
# @param converted_type [String or nil] The datatype of the result of the processor
# @param converted_bit_size [Integer or nil] The bit size of the result of the processor
def initialize(processor_name, result_name, converted_type = nil, converted_bit_size = nil)
super()
@processor_name = processor_name.to_s.upcase
@result_name = result_name.to_s.upcase.intern
if ConfigParser.handle_nil(converted_type)
@converted_type = converted_type.to_s.upcase.intern
raise ArgumentError, "Unknown converted type: #{converted_type}" if !BinaryAccessor::DATA_TYPES.include?(@converted_type)
end
@converted_bit_size = Integer(converted_bit_size) if ConfigParser.handle_nil(converted_bit_size)
end
# @param (see Conversion#call)
# @return [Varies] The result of the associated processor
def call(value, packet, buffer)
packet.processors[@processor_name].results[@result_name] || 0 # Never return nil
end
def to_s; end # Not shown for brevity
def to_config(read_or_write); end # Not shown for brevity
end
end
First of all note that ProcessorConversion inherits from the Conversion base class. This is very similar to the WatermarkProcessor inheriting from the Processor base class. Again, there is an initialize method and a call method. The initialize method requires the processor_name and result_name and takes optional parameters that help describe the converted type. Let’s see how these map together in our definition.
Our config file looked like the following:
READ_CONVERSION processor_conversion.rb TEMP1WATER HIGH_WATER
This passes TEMP1WATER and HIGH_WATER as processor_name and result_name into initialize:
def initialize(processor_name, result_name, converted_type = nil, converted_bit_size = nil)
We store the processor name and result name into Ruby instance variables (first turning them into upper case strings). We additionally turn the result name into a Ruby symbol by calling intern on it. This allows us to match the symbol names we used in the WatermarkProcessor code.
All Conversion classes also implement the call method except with a slightly different signature. In addition to the packet and buffer being passed, the raw value is returned. The ProcessorConversion class uses the packet instance to access the processors hash by the given processor name and then accesses the results hash by the passed result name. We add a ‘|| 0’ which does a logical OR on the initial result to ensure that we don’t return a nil value as a result of the conversion.
Custom Processor
So how could we implement our own Processor? Let’s say you had some telemetry points that you wanted to average and report that averaged value as a new telemetry item. This is useful because you can then add limits to this new item and act on its value in scripts without having to constantly perform the averaging operation.
First create your new Processor class. Let’s call it MeanProcessor. This code should go into a file called mean_processor.rb and can either live in one of your target/lib folders or since it’s generic we can put it in the top level /lib directory in our project.
require 'cosmos/processors/processor'
module Cosmos
class MeanProcessor < Processor # @param item_name [Array<String>] The names of the items to mean
def initialize(\*item_names) # the splat operator accepts a variable length argument list
super(:CONVERTED) # Hard code to work on converted values
@item_names = item_names # Array of the item names
reset()
end
def call(packet, buffer)
values = []
@item_names.each do |item|
values << packet.read(item, :CONVERTED, buffer)
end
@results[:MEAN] = values.inject(0, :+).to_f / values.length
end
# Reset any state
def reset
@results[:MEAN] = []
end
# Convert to configuration file string
def to_config
" PROCESSOR #{@name} #{self.class.name.to_s.class_name_to_filename} #{@item_names.join(' ')}\n"
end
end
end
This class introduces some new Ruby syntax. Since we want to accept any number of items to average we have to accept a variable number of arguments in our initialize method. The ruby splat operator (or star operator) does this and places the arguments into a Ruby array. We store these names and then use them in our call method to perform the mean. I’m using a cool feature of Ruby’s Enumerable mixin, which is part of Array, to sum up the values (starting with 0) and then dividing by the number of values we have to get the mean. Note I’m also calling to_f to ensure the numerator is a floating point number so we do floating point math during the division. Integer division would truncate the value to an integer value.
First to use this new processor you need to require it in your target’s target.txt configuration file:
REQUIRE mean_processor.rb
Then delcare the processing in your configuration definition as follows:
TELEMETRY INST HEALTH_STATUS BIG_ENDIAN "Health and status from the instrument"
... # See demo configuration
ITEM TEMPS_MEAN 0 0 DERIVED "Mean of TEMP1, TEMP2, TEMP3, TEMP4"
READ_CONVERSION processor_conversion.rb TEMPMEAN MEAN
PROCESSOR TEMPMEAN mean_processor.rb TEMP1 TEMP2 TEMP3 TEMP4
We define the processor on the INST HEALTH_STATUS packet and pass in 4 items to average. We also define a new derived item called TEMPS_MEAN which uses our previously described processor_conversion to pull out the MEAN value that we calculated. The result is shown in this PacketViewer screen shot:
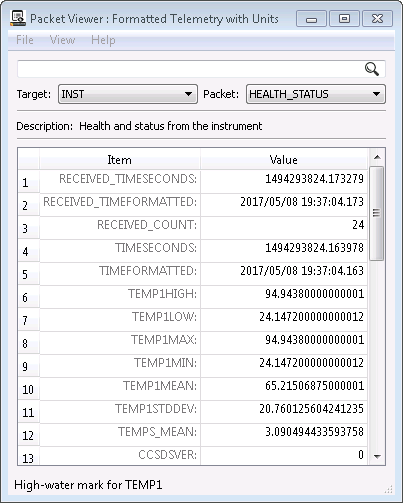
Creating a custom processor definitely requires you to dive into the COSMOS API and play with the underlying Ruby code. Hopefully the existing processor code and this blog post helps you to derive whatever telemetry points you need.
If you have a question which would benefit the community or find a possible bug please use our Github Issues.